I’ve been working on RESTifying my website management software a little since I want to learn a little bit about XUL and thought writing a XUL interface to manage my site would be a fun project. A clean RESTful HTTP interface is a great way to allow a client side application to talk to the server.
I quickly ran into a problem however. My software already placed resources at the center of the system, but as well as just storing the resource content data it also stores some metadata about that resource. So my problem was that sometimes I want to fetch the resource data and other times it’s metadata.
As with all good architectures, there are a number of ways of doing the same thing. I couldn’t decide on which was the best, there are multiple ways of asking for the metadata rather than the resource content, and multiple ways of delivering it.
Requesting metadata
Metadata response
So the question was, which of these was the best, most meaningful, more RESTful solution?
I liked the idea of sending a HTTP HEAD request and getting custom headers back with the meta data. HTTP headers make perfect sense for metadata, since they are name/value pairs too, and HEAD makes sense since we’re asking for header information only and we don’t want the overhead of sending all the metadata with every HTTP response.
I also liked the idea of creating a new HTTP method for getting back the metadata. This would allow the metadata to be sent in the response body thus opening up content negotiation so we could return the metadata in multiple formats if required.
The solution I decided upon… none of the above.
It suddenly dawned on me that I wasn’t thinking in a RESTful way. It’s very easy to fall back into a procedual way of thinking when what you really need to do is take a step back and re-factor things into more resources. So that’s what I did.
On retrospect it’s obvious that metadata for a resource is another resource entirely, it just so happens to relate to an existing resource. With that change implemented I suddenly have HTTP GET and PUT methods for recieving and updating resource metadata, as well as POST for appending a single piece of metadata and DELETE for removing all metadata.
So the moral of this story, think RESTfully, at all times. Hit a problem, backtrack and think about it from a resource/URL perspective. HTTP is simple, it doesn’t do very much, but that’s its power, don’t try to shoehorn complex ideas onto HTTP requests, break them down into simpler parts that can be modelled using REST and HTTP, and you’ll save yourself a lot of pain and come out of it with a more elegant RESTful system.
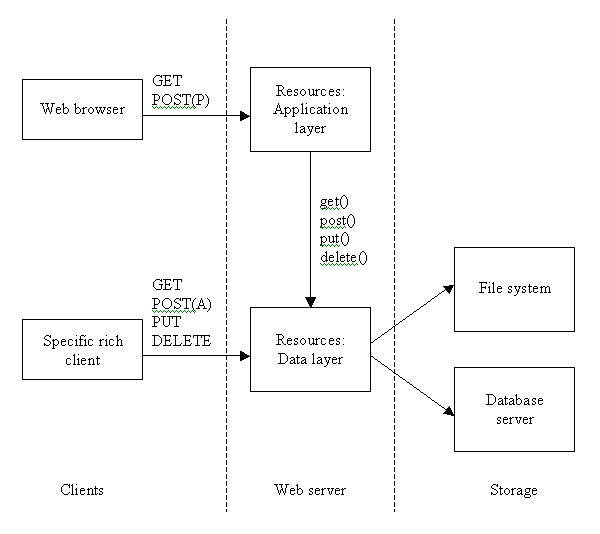
Today on the list was a post by Donald Strong that describes something that I’ve thought for a while but never coherently enough to put into words. There are two types of transaction within a REST system.
The first uses GET and POST(p) in what Donald describes as an untrusted transaction, the kind of transaction carried out everyday by the Web browser. The client has no direct access to manipulate resources but POSTs to a URL that processes the input and changes resource states as needed. The client is dumb while the server is intelligent, making sure that resources are always left in a valid state.
The second transaction type is trusted, using GET, PUT, POST(a) and DELETE, the types of transactions that Web services and rich clients want to perform. The client has total control over the servers resources in rather the same way as a SQL database client does. In this case the server is dumb with reguard to the resources and the client is intelligent.
Read Donalds post for more in depth information and a better explaination (complete with ASCII art).
What Donald then goes on to say is that if you use these two types of transaction together you end up with your classic 3 tier software architecture. The dumb client acts as the presentation layer talking to a server via GET and POST(p). This server is the application or business layer, doing all the heavy lifting and manipulating state by talking via GET, PUT, POST(a) and DELETE to another server, the data layer.
Now this is very clever, but when I think about it, it is what I’ve been thinking all along. Kind of. My theory has always been that there is no harm using POST(p) on a “do some process” URL to carry out a PUT, POST(a) or DELETE on the Web browsers behalf. It’s the structure that Tonic uses, all resources on the server can be manipulated by the four HTTP methods, but they can also be changed via GETting a HTML form from a “process this” URL and then POSTing data to it. All this URL does is manipulate the sites resources (files in this case) using the standard four methods (although not via HTTP since it’s on the same server).
In this setup, the “process” URLs HTML representations are the user interface, the “process” URLs processing code is the business logic, and the resources we’re manipulating are our data. This makes it very easy for us to bolt a new frontend onto our system in place of our HTML (for example a XUL interface, a shell script, or a GUI application) by automatically giving us a nice RESTful interface.